피벗 테이블(Pivot Table)은 데이터프레임의 특정 열을 기준으로 데이터를 요약하고, 집계하여 재구성하는 기능입니다. 엑셀의 피벗 테이블과 유사하게, 판다스의 pivot_table 메서드를 사용하여 데이터를 쉽게 분석하고 요약할 수 있습니다.

피벗 테이블의 주요 기능
- 행 및 열 기준 설정: 특정 열을 기준으로 행과 열을 구성할 수 있습니다.
- 집계 함수 적용: 데이터를 요약할 때 사용할 집계 함수를 지정할 수 있습니다 (예: 평균, 합계, 개수 등).
- 다중 집계: 여러 집계 함수를 동시에 사용할 수 있습니다.
기본 사용법
pivot_table()의 기본 형식은 다음과 같습니다

예제
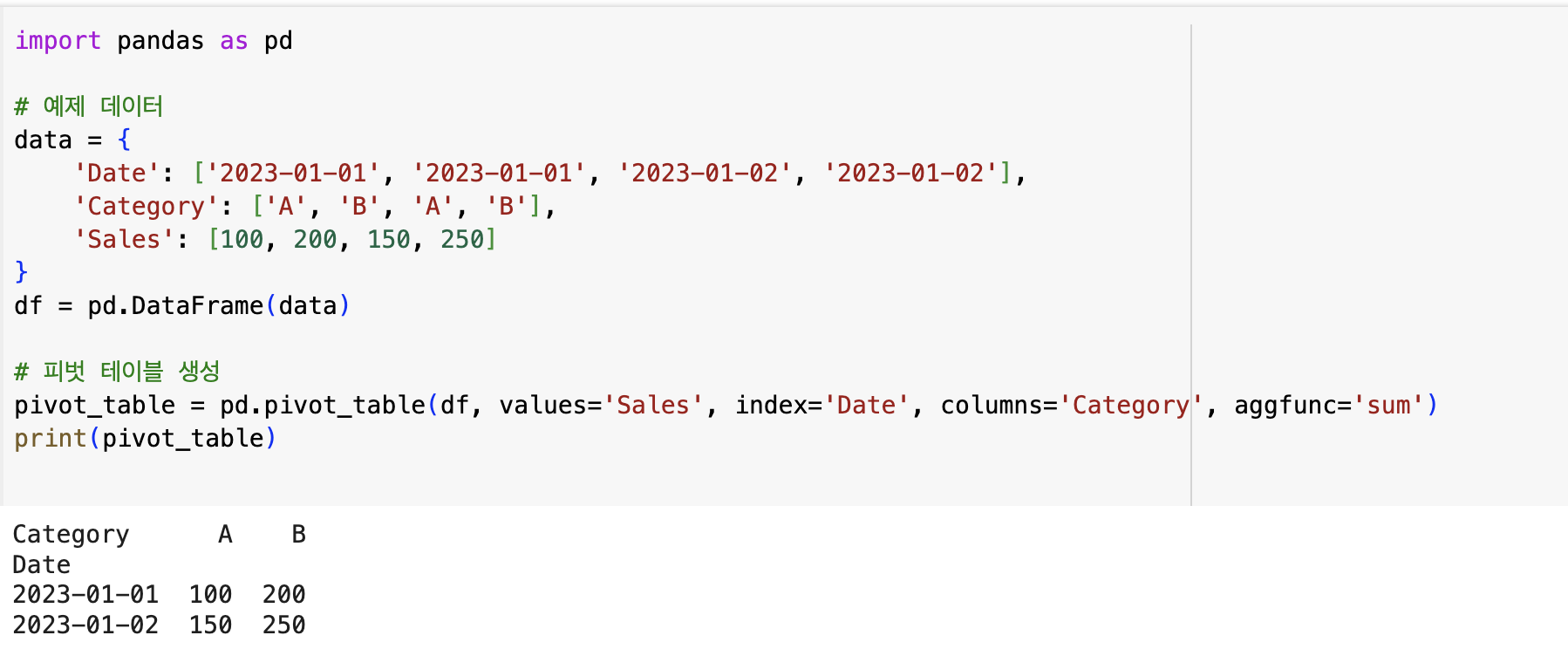
설명
- values: Sales 열을 집계할 대상 열로 지정했습니다.
- index: Date 열을 행 인덱스로 사용하여 날짜별로 요약합니다.
- columns: Category 열을 열 기준으로 사용하여 카테고리별로 나눕니다.
- aggfunc: sum을 사용하여 각 날짜-카테고리 조합의 Sales 합계를 계산합니다.
주요 파라미터
- values: 집계할 열을 지정합니다.
- index: 행으로 사용할 열을 지정합니다.
- columns: 열로 사용할 열을 지정합니다.
- aggfunc: 집계 함수를 지정합니다 (sum, mean, count, min, max 등).
- fill_value: 결측값을 특정 값으로 채울 수 있습니다.
- margins: True로 설정하면 총합을 계산하는 행과 열이 추가됩니다.
다중 집계 함수 사용
여러 집계 함수를 동시에 사용할 수도 있습니다.

요약
- 피벗 테이블은 데이터를 요약하고 다양한 집계 함수를 적용하여 유용하게 시각화할 수 있는 도구입니다.
- 다중 집계 및 행/열 기준 설정으로 여러 차원의 데이터를 한 번에 분석할 수 있습니다.
== 실습 코드 ==
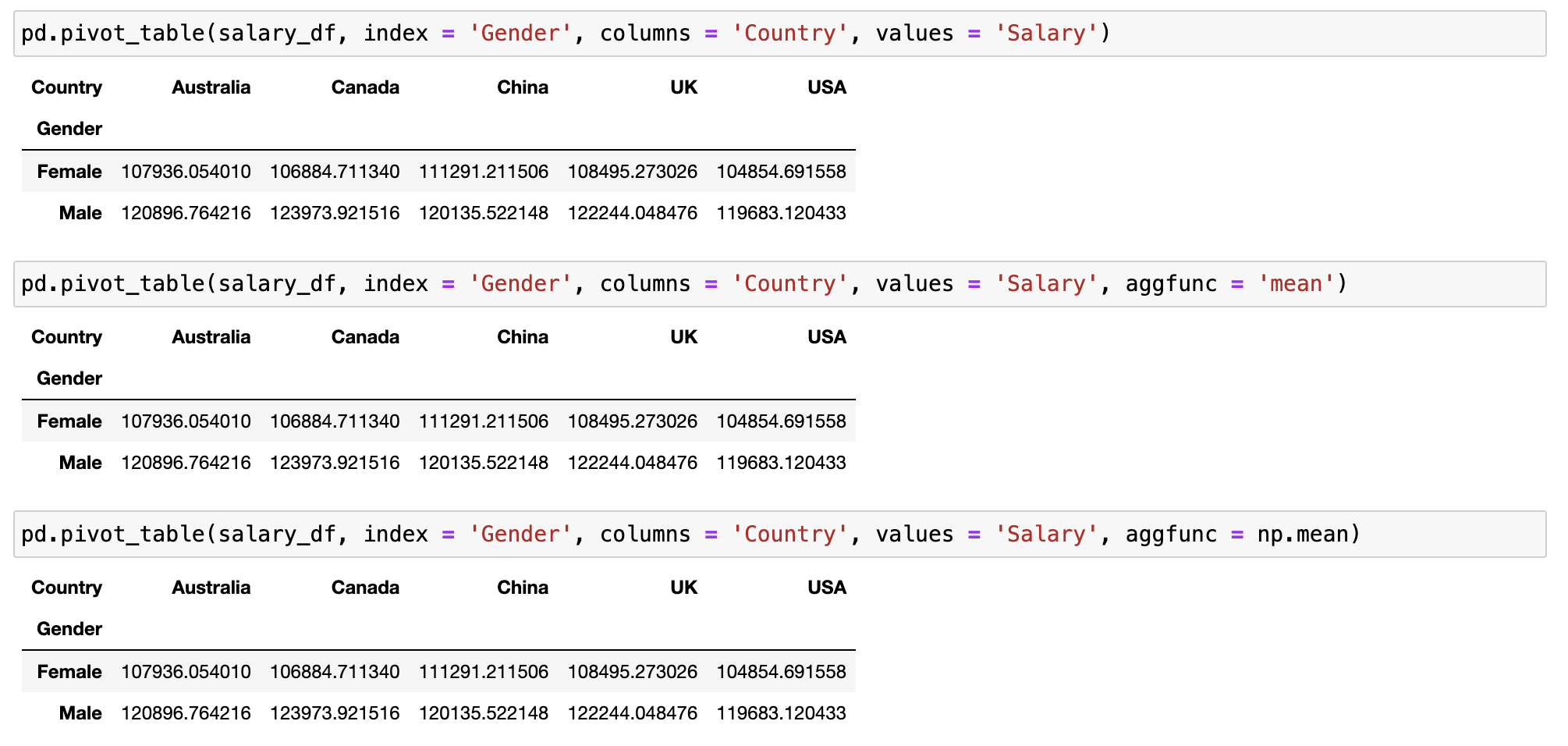

groupby와 pivot_table 비교
groupby와 pivot_table은 둘 다 데이터 요약에 사용되지만, 목적과 기능에서 몇 가지 차이점이 있습니다.
각 메서드의 특성과 차이점을 살펴보겠습니다.
1. 기본 목적과 용도
- groupby: 데이터를 특정 열을 기준으로 그룹화하고 집계하여 열 형태 그대로 요약할 때 사용합니다. 결과는 기본적으로 인덱스가 있는 데이터프레임으로 반환되며, 후처리나 추가 작업을 통해 행과 열의 구성을 변경할 수 있습니다.
- pivot_table: 행과 열을 자유롭게 재구성하여 2차원 형태로 데이터를 요약하고자 할 때 사용합니다. 피벗 테이블은 index, columns, values의 지정으로 데이터를 행렬처럼 나타내는 데 적합합니다.
2. 사용 방식의 차이
- groupby: 그룹화할 열을 지정하고 집계 함수(sum(), mean(), 등)를 바로 호출합니다.
- pivot_table: index, columns, values 파라미터를 통해 행과 열의 구조를 지정하여, 2차원 형태의 결과를 쉽게 만듭니다.
3. 다중 집계와 다중 열 그룹화
- groupby: agg() 메서드를 사용하여 여러 집계 함수를 동시에 적용할 수 있으며, 여러 열을 기준으로 그룹화할 수 있습니다.
- pivot_table: 다중 집계를 위해 aggfunc에 리스트를 전달하여 여러 집계 함수를 지정할 수 있으며, 여러 index와 columns 기준으로 그룹화가 가능합니다.
4. 결측값 처리
- groupby: 결측값을 자동으로 처리하지 않으며, 결과에 결측값이 포함될 수 있습니다.
- pivot_table: fill_value 파라미터를 통해 결측값을 특정 값으로 대체할 수 있습니다.
예제 비교
같은 데이터를 groupby와 pivot_table로 요약하는 예제를 살펴보겠습니다.
예제 데이터


차이점 요약
- 결과 형식: groupby는 일반적인 데이터프레임 형태로, pivot_table은 행렬처럼 출력됩니다.
- 열 구성 및 재배열: pivot_table은 행과 열을 자유롭게 재배열할 수 있지만, groupby는 기본적으로 열을 기준으로 그룹화한 데이터를 반환합니다.
- 결측값 처리: pivot_table은 결측값을 fill_value로 쉽게 채울 수 있습니다.
- 다중 집계: pivot_table의 aggfunc를 통해 다중 집계를 간편하게 지정할 수 있습니다.
따라서, 데이터를 2차원으로 정리해보고 싶다면 pivot_table을,
일반적인 그룹화 작업을 수행하고자 한다면 groupby를 사용하는 것이 좋습니다.
피벗 테이블(pivot_table)과 피벗(pivot) 비교
피벗 테이블(pivot_table)과 피벗(pivot)은 둘 다 데이터프레임을 재구성하는 데 사용되지만, 기능과 목적에 약간의 차이가 있습니다.
1. pivot
- 기본 기능: 데이터를 특정 열을 기준으로 행과 열을 재구성합니다.
- 제한 사항: pivot()은 index, columns, values 파라미터에 지정된 값들이 고유해야 합니다. 즉, 동일한 index와 columns 조합에 여러 값이 있으면 오류가 발생합니다.
- 주용도: 단순히 데이터의 구조를 바꾸어 새롭게 배치할 때 사용됩니다.
요약 차이점
- 중복 데이터 처리:
- pivot: 중복이 없는 고유한 데이터에만 사용 가능.
- pivot_table: 중복 데이터도 처리 가능하며, 집계 함수를 통해 요약.
- 집계 기능:
- pivot: 단순히 구조를 재배열하는 데 사용.
- pivot_table: 중복된 데이터에 대해 집계와 요약이 필요할 때 유용.
따라서, 중복된 값이 없고 데이터의 구조만 바꾸려면 pivot()을, 중복 데이터가 포함되어 있고 집계가 필요하다면 pivot_table()을 사용하는 것이 좋습니다.




Aggregation : 여러 데이터 포인트를 요약하고, 그룹화하여 새로운 통계 또는 정보를 추출하는 과정입니다.
- agg( ) 함수: 다양한 집계 함수를 한 번에 적용하여 다양한 요약 통계를 얻을 수 있습니다.
반응형
'데이터사이언티스트 Data Scientist' 카테고리의 다른 글
| 스케일링 (Scaling) (0) | 2024.11.04 |
|---|---|
| 원 - 핫 인코딩 - 범주형 데이터를 수치형 데이터로 변환하기 (1) | 2024.11.04 |
| melt 메소드 (0) | 2024.11.04 |
| 파이썬 - groupby (1) | 2024.11.04 |
| 데이터 병합 하기 - concat, merge, join (1) | 2024.11.04 |



